 Image generated by Midjourney
Image generated by Midjourney
Generative AI & Foundation Models: A Look into the Future
Enterprise View of Generative AI
Looking back over time, what are the technological discoveries that truly transformed society? You could argue that the Printing Press, Steam Engine, Electric Light, Automobile, Antibiotics, Nuclear Energy, and the Internet would all be on that list. And Generative AI (or “GenAI”) may be the next candidate to be included due to its potential to greatly alter so many parts of our lives. The answer to that initial question, ultimately, will be answered in time. What is not up for debate, of course, is the massive opportunity and responsibility GenAI creates for all of us.
Given its potential for such profound impact, we at Intel Capital believe all of us – particularly the technology industry – need to be learning, and talking about GenAI and its implications, as much as possible. To help foster that discussion, we plan to continue an ongoing conversation through blog posts and discussions. Below is our initial post on the topic. Have thoughts? Drop us a line. We’d love to chat.
Generative AI or “GenAI” dominates discussions today, whether you’re in a room full of technology founders, investors or even regulators. Most of the early cynicism that GenAI might be another “web3” or “crypto” opportunity has subsided. GenAI’s growing popularity is undeniable – it seems that almost everyone is interested in building solutions, discovering how to use and monitor them, and inevitably regulating them to ensure GenAI is productive rather than harmful.
Intel Capital has been investing in AI for over a decade. GenAI isn’t new to us either. In fact, we have long been investors in GenAI-based or focused companies like Anyscale, Common Sense Machines, Inworld AI, Landing AI, Lilt and SambaNova Systems, among others.
Given all the excitement, hype and confusion about GenAI, where it came from and what it can actually do, we’d like to provide some context and a bit of history here - with the goal of helping founders and users discover their GenAI opportunity.
What is GenAI?
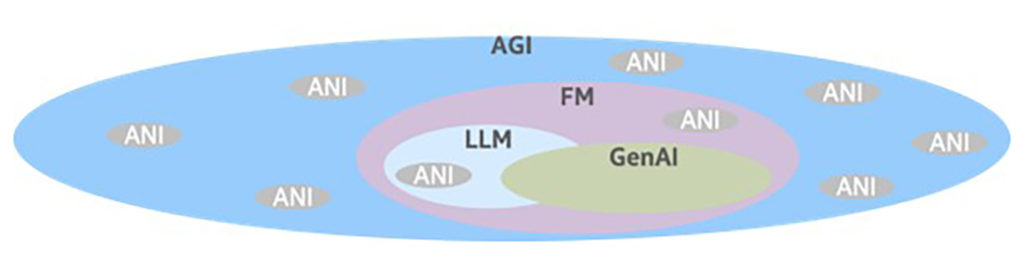
The term GenAI is overused today and has become, correctly or incorrectly, a synonym for Artificial Intelligence (AI) or Large Language Models (LLM).
Artificial General Intelligence (AGI) is a hypothetical intelligent agent which can understand or learn any intellectual task that humans or other animals can. We are still far away from AGI. Most AI solutions introduced in the last half-century are Artificial Narrow Intelligence (ANI) and focus on solving one problem or applying it to one task.
Lately, Foundation Models (FM) that can perform more than one task have emerged. FMs are large AI models trained on a vast quantity of data at scale, resulting in a model that can be used for a wide range of downstream tasks. An LLM is a unique type of FM – a language model that can recognize, summarize, translate, predict, search, rewrite, translate, and generate text and other content based on knowledge gained from massive datasets. When people talk today about GenAI, they are typically talking about LLMs. Nevertheless, other types of foundation models exist for computer vision and speech, and we may even see FMs for other types of data or domains in the future.
FMs can generate new data that does not currently exist in the training data, hence “Generative AI.” For example, a new image of the Golden Gate Bridge was created in Picasso’s painting style. GenAI can produce highly realistic and complex content that mimics human creativity. However, generating content is not the only use of FMs. It can also handle traditional ANI workloads, for instance, entity extraction, summarization, object detection, image classification, and more. This versatility allows practitioners to replace a variety of disparate models – each requiring a unique data set, training, and maintenance – with just one FM.
Brief History of Foundation Models
Foundation models, especially LLMs, transformed the way models are created and used. In 2017 Google released a paper called Attention Is All You Need. This paper established the foundation of LLMs by introducing Transformer, a new neural network architecture based on attention. Before the Transformer architecture, algorithms were trained for each specific task, which meant that a data scientist needed to gather proprietary data, pick algorithms, and execute a training process. Since transformer-based models were introduced, language models have become reusable. Not only have language models continued to improve in accuracy but are also trained on a vast amount of public data and created a general language knowledge that can be reused for different uses. This expanded access to trained models, making it easier and faster to deploy AI solutions by AI experts. In August 2021, the term foundation model (FM) was officially coined by The Stanford Institute for Human-Centered Artificial Intelligence’s (HAI) Center for Research on Foundation Models (CRFM).
GenAI: Will the best model win?
Despite remarkable advances since Transformers were introduced, AI models are far from an off-the-shelf product. AI models are a core building block of a product, but to be a full-fledged solution that a customer can readily buy and use, it would require more building blocks that translate the model value into business or consumer value. Historically, AI companies have done a poor job of providing these solutions. Machine learning has existed in the industry for several decades and the deep learning breakthrough happened a decade ago, but we still have only a small number of AI companies that have crossed $100M in recurring revenue and even fewer that have achieved impressive exits for their founders or investors. A company that attempts to differentiate itself solely based on the AI model at the core of its product, and competes on model performance alone, will, in our opinion, have a very difficult time finding long-term success.
The fleeting advantage of one model over another was recently illustrated very clearly. In November 2022, OpenAI introduced ChatGPT, which set a record for the fastest-growing user base, crossing 100 million active users in two months. Open AI offers a full-stack product with a prompt layer and an interface with an AI model at its core. While enterprises have used AI for B2B cases to reduce costs and increase revenue for years, consumers did not have the same access. On the B2C side, AI was embedded within the product and wasn’t a product itself. ChatGPT changed that by offering a B2C full-stack product that lets anyone use AI directly.
Data scientists, a small, highly skilled community, dominated the early days of deep learning. FM model-based solutions open the door for a vastly large pool of developers and consumers to use AI. OpenAI’s solution demonstrated the opportunity before us all, but it also exposed the myriad challenges to building a business and the opportunities which exist in solving them.
Enterprise Needs
When an enterprise deploys a software solution, including LLMs, there are several prerequisites for enterprise software-like compatibility with the company’s IT infrastructure, security certificates, logging, and documentation:
- Fine-tuning an FM involves adjusting and adapting a pre-trained model to perform specific tasks. It requires training the model further on a smaller, targeted dataset that is relevant to the desired task. General-purpose GenAI tools like ChatGPT are like Swiss Army Knives for AI use cases. However, enterprise use cases require a surgical knife that does one job very well. Given that most LLMs are trained on large corpora of public data, the models may lack an understanding of company- or industry-specific terminology. Enterprises optimize the model to their specific use cases by fine-tuning using instruction tuning, reinforcement learning through human feedback or other methods.
- AI Explainability allows users to understand and trust the results and output created by machine learning algorithms. FMs are used for tasks ranging from generative (e.g., content creation) to discriminative (e.g., classification, sentiment analysis). For generative tasks, while there is some room for what a “correct” result is, significant deviation from reality (e.g., by hallucinations) can be a critical issue for enterprises. For discriminative tasks, enterprises typically prefer the ability to explain how a certain result was derived. Moreover, in certain industries like consumer finance, being able to explain the logic behind discriminative models may be a regulatory requirement.
- Multimodality in AI combines multiple types of data to create tables, images, text and more, enabling the precise prediction of real-world problems. Enterprises have access to data in several formats and LLM solutions that support only unstructured text data are not enough - it’s critical that the models are able to extract data from images and tables to ensure the highest quality outcome.
- Containerized Models bundle together an application's code with all the files and libraries needed to run on any infrastructure. Foundation models remove much of the complexity of collecting data and training models but add other types of complexity. An enterprise needs building blocks that will help bridge the gap from the AI model to the solution; the enterprise requires building blocks that will help fine-tune the model with confidential data, build the prompting layer (an API layer), manage data embedding in a vector database, and optimizing hardware to reduce the total cost of ownership. The enterprise needs a containerized, optimized solution that includes all the building blocks needed to develop and run foundation models.
- Run Everywhere, in the cloud or on-prem, via SaaS or in your VPC. Some AI solutions focus on productivity and marketing data, while others may leverage confidential data to improve product development and increase revenue. The sensitivity of the task and data directly influences whether the foundation model is run in the cloud, SaaS, VPC or on-premises. A full-stack foundation model product needs to be able to run anywhere the customer requires, and a SaaS-only solution will drastically limit the GenAI enterprise use cases.
- Privacy and Security of proprietary data is a top concern of enterprises looking to use foundation models. In the most common modality of using closed-source FMs like GPT-4, users are required to pass on potentially sensitive and confidential information through the FM’s API. One concern is that such data may be used by FM providers to train their models, which could pose a risk to the competitive advantage that enterprise customers have. Additionally, companies often worry about inadvertently leaking sensitive information such as Personally Identifiable Information. OpenAI has integrated privacy guardrails into its business offering,
;but it’s too soon to tell if the security efforts are sufficient enough to gain enterprise adoption. On the other hand, enterprises could consider using open-source models that they deploy within their infrastructure, with the tradeoff being an increased complexity of implementation.
How Enterprises Leverage Foundation Models
Looking ahead, five to ten years from now, how will GenAI be used in the enterprise? Here’s our prediction. Due to the nature of the AI community, algorithms will be commoditized; any algorithm advantage will not last long. We are not anticipating that one model will rule all, but rather, we will have different foundation models for different data types/segments, which are generalized, and other models that are specialized for a specific task.
If you visit db-engines ranking, you will find hundreds of databases to use; they are all divided into twenty different models, including relational, key-value, graph, etc. Each model has its advantages. For example, some are in-memory databases with fast data retrieval, while others scale out to several servers and can store and retrieve huge datasets. A singular database cannot execute all enterprise workloads; an enterprise uses a variety of databases for different workloads. Once an enterprise chooses a database for a specific data type or workload, it promotes the adoption of the same database for similar use cases, thereby minimizing the necessity of supporting numerous technologies. We anticipate GenAI will follow the same pattern; there is no one-size-fits-all solution, and different models will be used for different use cases.
We believe an enterprise will implement a handful of FM sets as an Enterprise Intelligence Layer (some may call it an Enterprise Brain) that will serve dozens or even hundreds of use cases. In some applications, the FM will replace traditional ML solutions like entity extraction, and in others leverage new uses, like semantic search.

Build vs. Buy, SaaS vs. Subscription
The use case characteristics, such as the uniqueness within the industry or the sensitivity of data, will have the most significant impact on the decision to build vs. buy a solution. When considering a purchase, you may face a choice between a SaaS solution and a subscription offering. If your goal is to launch a marketing campaign translation and the data involved is not sensitive, opting for a SaaS solution would likely be cost-effective and speed up the resolution time. On the other hand, if you're a manufacturer seeking to enhance line productivity by providing a search feature for technicians, you would also prefer to make a purchase. However, due to the sensitive and unique nature of the manufacturing data that requires customizing the model, you might decide to engage in a subscription implemented on-premises or within your public cloud VPN. This choice allows for fine-tuning of the model and addresses data privacy concerns.
Common Enterprise Use Cases
- Search: Enterprise search has always been the proverbial holy grail of knowledge management in companies. Historically, search within the enterprise was riddled with issues due to the absence of indexes and the inability to contextualize user input. FMs enable semantic search, a set of special techniques and algorithms to understand the relationships between words, the concepts they represent and how they relate to each other.
- Summarization: LLMs excel at condensing lengthy passages of text into concise summaries that capture essential information such as customer feedback, training materials, and legal terms.
- Natural Language Querying: An interesting emergent behavior of LLMs is their ability to convert natural language into code that can run on existing systems. Specifically, when applied to convert natural language to SQL, LLMs can help further accelerate the democratization of data by enabling a greater number of users to query data without the need for technical know-how.
- Content Creation: LLM-based applications are already being employed to create marketing copy and other creative assets. Increasingly, other types of content including requirements specifications, training manuals, test scripts, technical documentation, and audio and visual media could end up being generated through a combination of LLMs paired with relevant “knowledge engines.”
The select use cases listed above are only a handful of possible applications across most enterprises. Beyond these, we foresee a plethora of industry and function-specific deployments emerging.
Just Getting Started
We all have a ton of learning and work to do to realize the potential for GenAI in the enterprise. Plenty of the requirements mentioned above don’t exist yet, at least not for GenAI-based applications, and others will change completely given the pace and extent of change we’ve seen so far in this domain. Even where enterprises are starting to use GenAI – and those instances appear to be few and far between at the moment – they tend to treat GenAI similarly to people who treated early automobiles as “just a faster horse.”
For founders, users, other investors, or enterprise customers, we’d love to talk more, hear your feedback and see what we might do together.



