
The C³ Context Cost Curve
A practical framework for context engineering in LLM systems
Most teams building with large language models share the same instinct: If the model makes mistakes, add more context.
Early on, this works. Accuracy improves. Hallucinations drop. Demos get better.
Then something strange happens. Latency spikes. Outputs become inconsistent. Debugging turns into guesswork. And despite adding more context, the model performs worse.
This post introduces a practical framework for understanding why this happens, and provides concrete guidelines for context engineering based on conversations with practitioners building real-world LLM systems.
Context is not free
In most AI systems, context is treated as an unpriced resource. System prompts, conversation history, retrieved documents, user memory, and tool outputs are all stuffed into a single context window with the assumption that the model will sort it out.
In reality, context has real costs:
- Token cost (paid on every request)
- Latency (often tail latency)
- Failure surface area (hallucinations, contradictions, priority inversion)
The most reliable AI systems do not maximize context. They optimize it.
What counts as context?
Context is everything the model sees before it produces an output, including:
- System instructions
- Output schemas
- Retrieved documents
- User memory
- Conversation history
- Tool outputs
- Agent scratchpads
The most common mistake teams make is treating all of this as interchangeable text. It is not.
Introducing C³: Cold, Warm, and Hot Context
The C³ framework classifies context based on two properties:
- How often it changes
- How authoritative it should be
Cold Context
Stable, rarely changing, highest authority
Examples include:
- System prompts
- Policies
- Output schemas
- Hard constraints
Cold context defines the rules of the system. If it is wrong, the failure can be catastrophic.
Best Practices:
- Keep it minimal and surgical
- Prefer schemas and validators over prose
- Avoid long explanations and too many examples
Anti-pattern:
Pasting an entire policy document into the system prompt.
Warm Context
Slowly changing, moderately authoritative
Examples include:
- User preferences
- Long-term memory
- Project or workspace metadata
- Summarized conversation history
Warm context provides continuity, but it comes with risks:
- It grows without bounds
- It drifts over time
- It is often stale or partially incorrect
Best Practices:
- Retrieve it dynamically
- Summarize aggressively
- Label it as advisory rather than binding
- Track freshness and confidence
Anti-pattern:
Appending full conversation history indefinitely.
Hot Context
Ephemeral, volatile, lowest authority
Examples include:
- Current user input
- Tool outputs
- Agent scratchpads
- Intermediate reasoning artifacts
Hot context changes on every request and has the highest entropy. It is also the most likely to be wrong.
Best Practices:
- Enforce hard token caps
- Use structured tool outputs
- Automatically expire data
- Never blindly trust tool results
Anti-pattern:
Dumping every tool response back into the prompt.
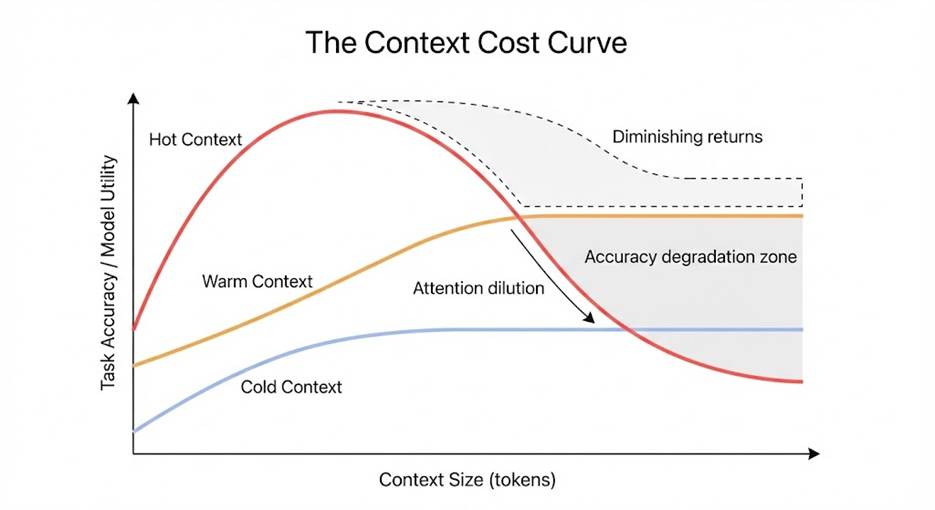
The Context Cost Curve
The key insight behind C³ is that context value grows sub-linearly, while context cost grows linearly or worse.
Early context additions dramatically improve accuracy. Past a certain point, returns diminish. Beyond that point, accuracy often declines.
This happens for several reasons:
- Attention dilution
- Conflicting signals
- Implicit priority inversion
- Larger hallucination surface area
Different context types hit this inflection point at different times:
- Cold context plateaus early
- Warm context later
- Hot context very early, often followed by a sharp decline
This relationship is the Context Cost Curve.
The C³ Context Stack
Not all context deserves equal weight. Reliable systems assemble context deliberately, from the highest authority to the lowest:
- Task instructions (cold)
- Output schemas and constraints (cold)
- Retrieved facts (warm)
- User or project memory (warm)
- Recent conversation (hot)
- Tool outputs and scratchpads (hot)
As you move down the stack:
- Authority decreases
- Volatility increases
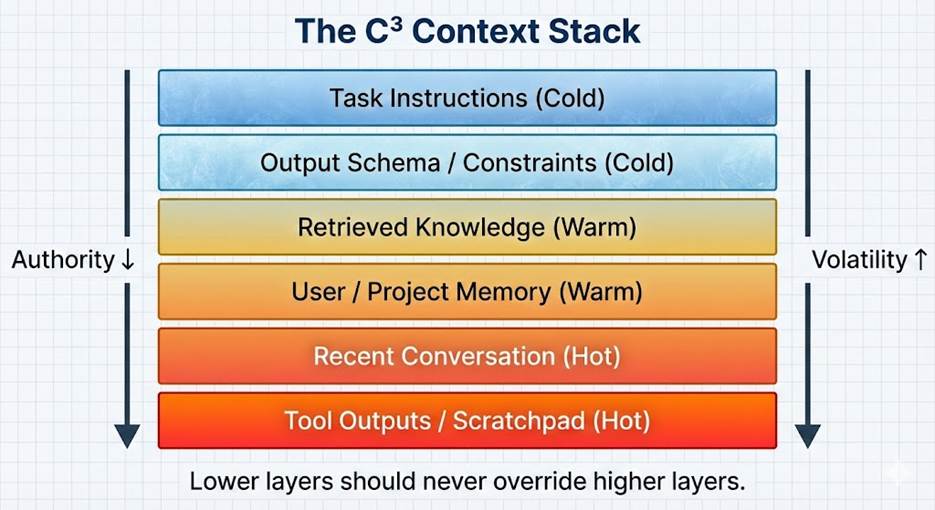
A simple rule follows: lower layers should never override higher layers. Most hallucinations are violations of this rule.
Operationalizing C³
Teams that take context seriously do a few simple things consistently:
- Tag context blocks as cold, warm, or hot
- Log context composition on every request
- Track accuracy relative to context size
- Enforce explicit token budgets
- Continuously summarize or decay warm context
In practice, most reliability issues in LLM systems do not come from model choice or prompt wording. They come from treating context as an unlimited buffer rather than a constrained design surface.
Once teams become explicit about what information deserves to be present, how long it should live, and how much authority it carries, much of the complexity disappears. Context stops being a source of surprises and becomes something you can reason about, measure, and improve.
If you are building an AI product and finding that reliability, latency, or evaluation quality degrades as you scale, I would welcome the chance to compare notes. I spend a lot of time working with teams navigating these exact problems and am always interested in learning from what others are seeing in the wild. Please reach out!


